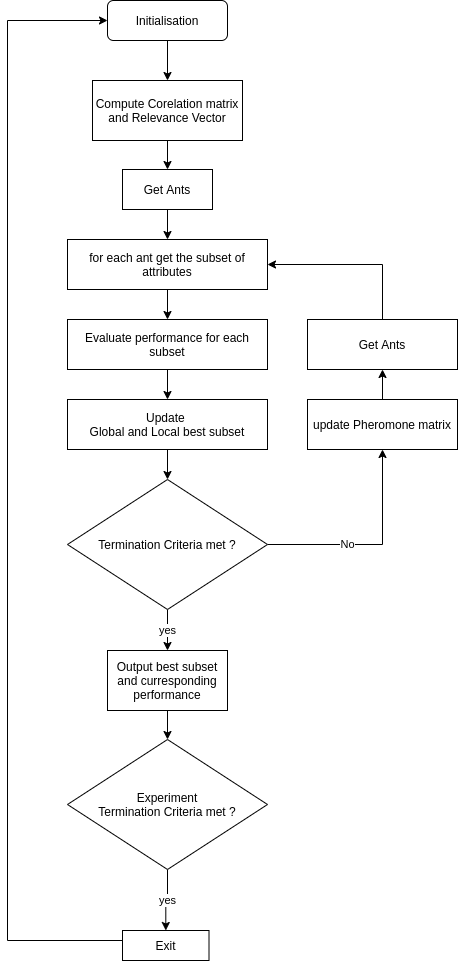
Algorithm:
Random forest (RF) is an ensemble of randomly constructed independent (and unpruned, i.e. fully grown) decision trees [Breiman]. It uses bootstrap sampling technique, which is an improved version of bagging. It is better than bagging and is comparable to boosting in terms of accuracy, but computationally much faster and more robust with respect to over-fitting noise than boosting and other tree ensemble techniques. Randomness is introduced into the RF algorithm in two ways: one in the sample dataset for growing the tree and the other in the choice of the subset of attributes for node splitting while growing each tree. Such a RF is grown in the following manner: For each tree, a Bootstrap sample (with replacement) is drawn from the original training data set. Pruning is not necessary in RF since bootstrap sampling takes care of the over fitting problem. This further reduces the computational load of the RF algorithm. After all the trees are grown, the kth tree classifies the instances that are OOB for that tree (left out by the kth tree). In this manner, each case is classified by about one third of the trees. A majority voting strategy is then employed to decide on the class affiliation of each case. The proportion of times that the voted class is not equal to the true class of case- ‘n’, averaged over all the cases in the training data set is called as the OOB error estimate. Now after growing the forest, if an unseen validation test dataset is given for classification, each tree in the random forest casts a unit vote for the most popular class in the test data. The output of the classifier is determined by a majority vote of the trees. The classification error rate of the forest depends on the strength of each tree and the correlation between any two trees in the forest. The key to accuracy is to keep low bias and low correlation among the trees. Random Forest can also be used to get an estimate of the variables that are important for classification. The weighted average of Gini reduction of a given variables at different nodes in a tree and at different trees provide quantitative information about Gini Importance.
Several authors have employed ACO for feature selection(references). Recently Kashef and Nezambadipour employed an advanced version of binary ACO incorporating correlation between features. Our modified and improved algorithm employs a synergistic combination of Correlation and Random Forest Gini importance, probabilistically employed as heuristics.
A modified version of the Binary Ant Colony Optimization algorithm is developed for feature selection. In Ant Colony Optimization technic for feature selection, features are considered as nodes of a graph and there is a link between all nodes. Ants start from a random node then depending on the weight of the links Ant moves to the next node, it stops after a predetermined number of hops. All the nodes traversed by the ant are selected. After all Ants finish traversing route, performance is analyzed for each selection of attributes. The best performing ant is rewarded by increasing the Pheromone level on all the links traversed by that Ant.
In BACO each attribute is assumed to have one of two states 0 and 1, hence the name Binary ACO. State 1 indicates that the feature corresponding to that state is selected while 0 indicates the feature is not selected. Now if we assume features as the nodes of a graph, between any two nodes four different types of links are possible. For example, say i and j are two nodes then, i0- j0, i0- j1, i1- j0, and i1- j1 are four different links representing different combinations of a selection of i and j. Unlike in classic ACO in this algorithm ants traverse all the attributes. Finally, we get a vector of 1s and 0s of length equal to the number of attributes along with list of attributes in order of traversal.
In this study, we also generate Heuristic Importance scores for each link which along with the Pheromone value is used to decide the next move for the ant. Three different methods [5] to generate Heuristics importance of link based on Correlation matrix and relevance vector are used. We have used normalized GINI importance of attributes as relevance vector.
-
Initialization
Algorithm parameters are set. For Heuristics information Correlation matrix and relevance vector are generated -
Generating ants and the feature subset
First ants are randomly assigned a node and a state. Then before each hop set of unvisited nodes is considered, the weight of the link to next hop is computed based on the pheromone level on that link and the importance of the next attribute. For each attribute, there are two different links possible from the current position of the Ant. The next attribute is either selected (link to 1 is selected) for not selected (link to 0 is selected). Weight of selection link is computed as the product of pheromone and feature importance score, while the weight of non-selection link is computed as a product if pheromone and [1 - feature importance score]. This way of computing the link weight increases the probability of selection of important attributes and reduces that for less important attributes. An Exploration-Exploitation parameter is set during initialization depending on which, method to choose the next node and state is decided.- Exploitation - In case of exploitation, the highest weighted link is chosen as the next move for the Ant.
- Exploration - In the case of exploration, random selection is done from a probability distribution. The probability of selection of each link is proportional to its weight.
-
Performance Measure
Classification is done based on the selected attributes by each ant and accuracy is computed by 5-fold cross-validation. But along with maximizing the accuracy, another objective is to minimize the redundancy in attributes, for this, a modified performance measure is used. The performance measure is evaluated for each ant. -
Updating the Pheromone matrix
Only the ant with the best performance measure value is rewarded by increasing the pheromone level on each of the links traversed by that ant, other links are punished by reducing the pheromone. -
The above steps are repeated till the stopping criteria is reached.
This experiment is repeated multiple times to get statistical information about the results.